Este caso práctico es el apéndice online del libro Customer Lifetime Value (CLV) - No todos tus clientes valen lo mismo: el cuaderno de trabajo, ejecutable de principio a fin, que complementa la narración de los capítulos 5, 6, 7 y 8. Te llevo de la mano por un dataset público (Online Retail II, del UCI Machine Learning Repository) y, sobre él, recorro el ciclo completo de un proyecto de CLV serio: primero, la mirada retrospectiva del capítulo 5 (auditoría preliminar, decisiones de limpieza, cohortes mensuales y RFM); después, el lado predictivo del capítulo 6 (calibración de BG/NBD y Gamma-Gamma, pAlive y valor esperado por cliente); luego, la validación honesta del capítulo 7; y, por último, la segmentación basada en valor que alimenta el capítulo 8. Construir, validar y accionar, en ese orden. Lo cierro persistiendo cinco artefactos que vas a cargar tal cual en los capítulos siguientes, sin volver a tocar nada.
NotaCómo está pensado este caso práctico
Lo importante de este caso práctico no es el código (que está, y es ejecutable), sino las decisiones. Cada una de las siete decisiones del caso (cuatro de limpieza y tres de modelado) aparece en un bloque fijo con cuatro campos: decisión, por qué, alternativas descartadas y consecuencias visibles. Si en tu proyecto real tomas otras decisiones, perfecto; lo importante es que las tomes a conciencia, las documentes y dejes un rastro defendible.
Para ejecutarlo, necesitas Python 3.10 o superior y las dependencias listadas en requirements.txt (en la raíz del proyecto). La forma recomendada es crear un virtualenv local y registrar su kernel:
A partir de ahí, quarto render ya encuentra el kernel libro-clv que pide el front matter de este caso práctico. La primera vez tarda un poco más, porque descarga el .xlsx original (unos 45 MB) desde UCI. Las siguientes, se va directo a leerlo de materiales/cap05/raw/.
El dataset que vas a usar (Online Retail II, alojado en el UCI ML Repository con id 502) contiene unas 1.067.000 líneas de pedido de un retailer online británico entre diciembre de 2009 y diciembre de 2011. La empresa vende regalos y artículos para el hogar, mitad a consumidores finales, mitad a pequeños mayoristas. No hay contrato, no hay suscripción, no hay nada parecido a una “fecha de baja”: cuando un cliente deja de comprar, simplemente desaparece. Eso lo convierte en el ejemplo de manual de un negocio deliberadamente no contractual, como ya te conté en el capítulo 5.
ruta = descargar_si_falta()# El xlsx tiene dos hojas (un año por hoja). Las cargo las dos y las concateno.hojas = pd.read_excel(ruta, sheet_name=None, engine="openpyxl")print(f"Hojas en el xlsx: {list(hojas.keys())}")df = pd.concat( [s.assign(_hoja=name) for name, s in hojas.items()], ignore_index=True,)# Renombro a *snake_case* para trabajar más cómodos internamente. Las columnas# originales del xlsx siguen siendo las del UCI; si quieres mantener esa# nomenclatura, cambia este bloque y ya está.df = df.rename(columns={"Invoice": "invoice","StockCode": "stockcode","Description": "description","Quantity": "quantity","InvoiceDate": "invoice_date","Price": "price","Customer ID": "customer_id","Country": "country",})df["invoice"] = df["invoice"].astype(str)df["stockcode"] = df["stockcode"].astype(str)df["invoice_date"] = pd.to_datetime(df["invoice_date"])df["importe"] = df["quantity"] * df["price"]print(f"Forma: {df.shape}")print(f"Rango temporal: {df['invoice_date'].min()} -> {df['invoice_date'].max()}")df.head(3)
Hojas en el xlsx: ['Year 2009-2010', 'Year 2010-2011']
Forma: (1067371, 10)
Rango temporal: 2009-12-01 07:45:00 -> 2011-12-09 12:50:00
invoice
stockcode
description
quantity
invoice_date
price
customer_id
country
_hoja
importe
0
489434
85048
15CM CHRISTMAS GLASS BALL 20 LIGHTS
12
2009-12-01 07:45:00
6.95
13085.0
United Kingdom
Year 2009-2010
83.4
1
489434
79323P
PINK CHERRY LIGHTS
12
2009-12-01 07:45:00
6.75
13085.0
United Kingdom
Year 2009-2010
81.0
2
489434
79323W
WHITE CHERRY LIGHTS
12
2009-12-01 07:45:00
6.75
13085.0
United Kingdom
Year 2009-2010
81.0
Las columnas son las que cabe esperar: identificador de factura, código y descripción del producto, cantidad, fecha de factura con marca temporal, precio unitario, identificador de cliente y país. El importe que añado por comodidad es simplemente quantity × price (negativo si la línea es una cancelación, cosa que veremos enseguida).
Auditoría preliminar
Antes de modelar nada, hay que auditar. Lo dije en el cap. 5 y lo repito aquí: si modelas sobre datos sucios, lo que sale del modelo te confirma lo que el modelo “ve”, y si lo que ve es ruido, te confirma ruido con un decimal extra. Empezamos contando.
volumenes = pd.Series({"Líneas totales": len(df),"Facturas únicas": df["invoice"].nunique(),"Clientes únicos (con ID)": int(df["customer_id"].dropna().nunique()),"Productos únicos (stockcodes)": df["stockcode"].nunique(),"Países distintos": df["country"].nunique(),"Filas sin Customer ID": int(df["customer_id"].isna().sum()),"Filas con Invoice tipo cancelación": int(df["invoice"].str.startswith("C").sum()),})volumenes
Líneas totales 1067371
Facturas únicas 53628
Clientes únicos (con ID) 5942
Productos únicos (stockcodes) 5305
Países distintos 43
Filas sin Customer ID 243007
Filas con Invoice tipo cancelación 19494
dtype: int64
porcentajes = pd.Series({"Filas sin Customer ID (%)": df["customer_id"].isna().mean() *100,"Filas de cancelación (%)": df["invoice"].str.startswith("C").mean() *100,})porcentajes.round(2)
Filas sin Customer ID (%) 22.77
Filas de cancelación (%) 1.83
dtype: float64
Dos cifras te tienen que llamar la atención. La primera, que una de cada cuatro líneas no tiene Customer ID. Es muchísimo: si lo ignoras y arrastras esas filas a un análisis de cliente, contaminas todo. La segunda, que hay un porcentaje pequeño pero no despreciable de filas que son cancelaciones (la convención del retailer es prefijar el Invoice con la letra C). Cada una de esas dos patologías necesita su decisión, y se las dedico en la sección 1.2.
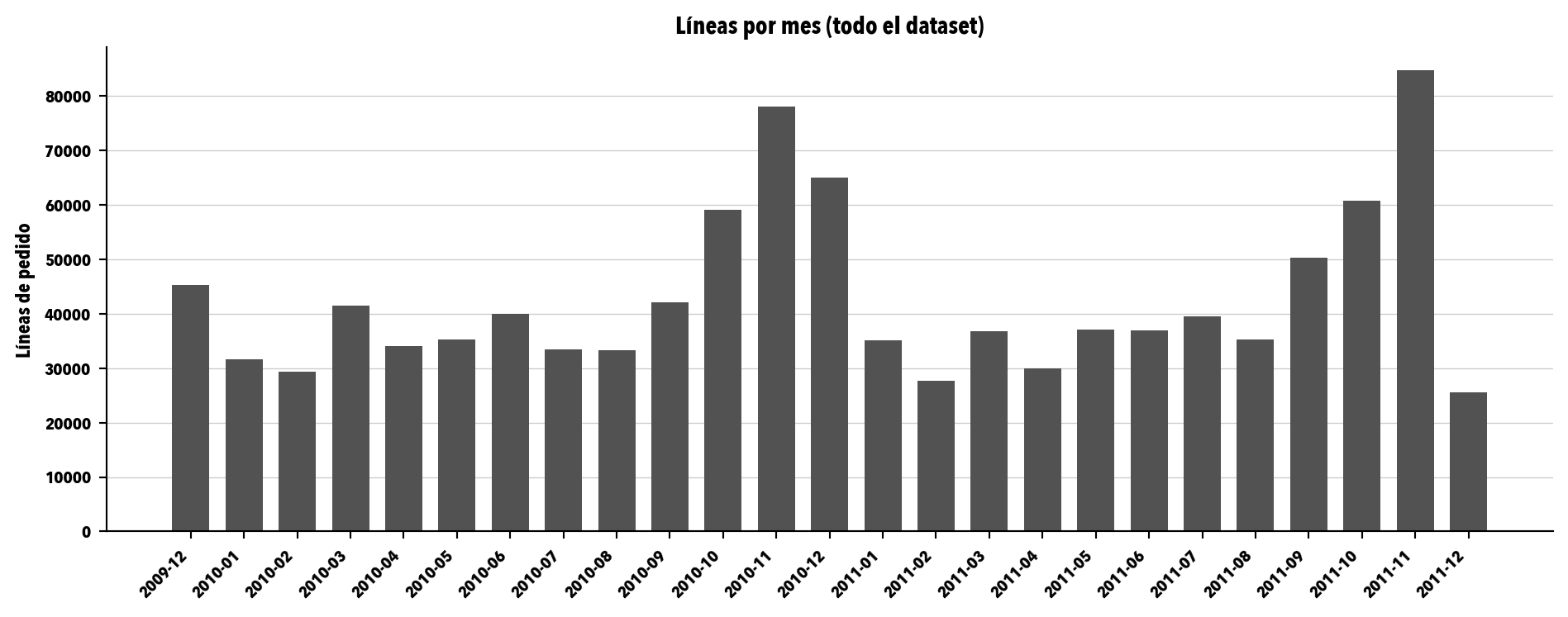
mensual = (df.assign(mes=df["invoice_date"].dt.to_period("M")) .groupby("mes") .size())fig, ax = plt.subplots(figsize=(10, 4))ax.bar(range(len(mensual)), mensual.values, color=GRISES_4[2], width=0.7)ax.set_xticks(range(len(mensual)))ax.set_xticklabels([str(m) for m in mensual.index], rotation=45, ha="right")ax.set_ylabel("Líneas de pedido")ax.set_title("Líneas por mes (todo el dataset)")ax.grid(axis="y", color=GRISES_4[0], linestyle="-", linewidth=0.5)ax.set_axisbelow(True)plt.tight_layout()plt.show()
Figura 1: Distribución mensual del número de líneas de pedido. El pico de octubre y noviembre es la huella del mayorista que se prepara para Navidad; el valle de finales de enero es la resaca de la misma temporada.
# Distribución de líneas por facturalineas_por_factura = df.groupby("invoice").size()print("Líneas por factura:")print(f" mediana = {lineas_por_factura.median():.0f}")print(f" media = {lineas_por_factura.mean():.1f}")print(f" p95 = {lineas_por_factura.quantile(0.95):.0f}")# Top paísesprint("\nTop 5 países (% de líneas):")print((df["country"].value_counts(normalize=True).head(5) *100).round(2))# Stockcodes "raros" (los que no son productos)patron_raro =r"^(POST|BANK CHARGES|AMAZON FEE|DOT|M|S|ADJUST|PADS|CRUK|TEST)$"raros_mask = df["stockcode"].astype(str).str.match(patron_raro, na=False)print(f"\nLíneas con stockcode 'raro' (no producto): {raros_mask.sum():,} "f"({raros_mask.mean()*100:.3f}% del total)")print("\nTop stockcodes raros:")print(df.loc[raros_mask, "stockcode"].value_counts().head(10))
Líneas por factura:
mediana = 9
media = 19.9
p95 = 66
Top 5 países (% de líneas):
country
United Kingdom 91.94
EIRE 1.67
Germany 1.65
France 1.34
Netherlands 0.48
Name: proportion, dtype: float64
Líneas con stockcode 'raro' (no producto): 5,297 (0.496% del total)
Top stockcodes raros:
stockcode
POST 2122
DOT 1446
M 1421
S 104
BANK CHARGES 102
ADJUST 67
PADS 19
CRUK 16
Name: count, dtype: int64
Los stockcodes raros son entradas que no son productos: gastos de envío (POST), comisiones bancarias (BANK CHARGES), comisiones de Amazon (AMAZON FEE), una categoría misteriosa de un solo carácter (M, S, D…), ajustes manuales (ADJUST, Manual), y similares. Aparecen como líneas en facturas mezcladas con producto real. Para esta primera vuelta los voy a dejar dentro, porque su contribución al revenue es marginal y su efecto sobre RFM es pequeño. En un proyecto real, conviene auditarlos uno a uno; lo dejo apuntado.
Las cuatro decisiones de limpieza
Llegamos al núcleo del caso práctico. Te recuerdo el leitmotiv que repito a lo largo del libro: decidir, documentar la decisión y dejar un rastro defendible. Cada una de las cuatro decisiones que verás a continuación está tomada a conciencia, y en cada caso te enseño qué pasaría si hubiera elegido cualquiera de las alternativas. Si tu proyecto real necesita otra decisión, repite el ejercicio: cuatro campos, ningún hueco.
Identificadores de cliente nulos
Aproximadamente una de cada cuatro líneas del dataset no tiene Customer ID. Es muchísimo. Antes de seguir adelante, hay que decidir qué se hace con esas filas.
ImportanteDecisión 1: filas sin Customer ID
Decisión. Las filas sin Customer ID se conservan en la auditoría preliminar (volúmenes, calendario, países, cesta) pero se excluyen de cualquier análisis a nivel de cliente: cohortes, RFM y los modelos del capítulo 6.
Por qué. La información agregada sobre la actividad del negocio (cuánto vende, cuándo, dónde, qué) sigue siendo válida con todas las filas. La información a nivel de cliente, por definición, no se puede construir sin identificador. Mezclar las dos cosas (asignar un ID común a todos los nulos, por ejemplo) introduce un “cliente desconocido” eterno y comprador compulsivo que contamina cualquier estadística de retención.
Alternativas descartadas. Excluir las filas desde el primer paso (pierdes contexto agregado útil) y tratar los nulos como un único cliente desconocido (contamina RFM y cohortes). Ninguna de las dos es defendible.
Consecuencias visibles. El siguiente bloque te enseña cuántas líneas y cuánto revenue caen del análisis de cliente al aplicar esta decisión.
filas_nulas = df["customer_id"].isna().sum()revenue_nulo = df.loc[df["customer_id"].isna(), "importe"].sum()revenue_total = df["importe"].sum()print(f"Líneas que caen del análisis de cliente: {filas_nulas:,} "f"({filas_nulas/len(df)*100:.2f}%)")print(f"Revenue asociado a esas líneas: {revenue_nulo:,.2f} "f"({revenue_nulo/revenue_total*100:.2f}% del total)")df_cliente = df.dropna(subset=["customer_id"]).copy()df_cliente["customer_id"] = df_cliente["customer_id"].astype(int)print(f"\nTabla resultante df_cliente: {df_cliente.shape}")
Líneas que caen del análisis de cliente: 243,007 (22.77%)
Revenue asociado a esas líneas: 2,638,958.18 (13.68% del total)
Tabla resultante df_cliente: (824364, 10)
Cancelaciones
Las cancelaciones se reconocen porque su invoice empieza por la letra C y su quantity es negativa.
ImportanteDecisión 2: cancelaciones
Decisión. Las cancelaciones se mantienen como filas independientes con quantity e importe negativos. El neto sale solo al agregar por cliente o por periodo. No se intenta aparearlas con la venta original.
Por qué. Es la opción más transparente, más simple y más defendible. La cancelación deja huella en el calendario (forma parte de la actividad del cliente con el negocio) y el neto agregado refleja correctamente el valor del cliente. El apareo cancelación-venta es imperfecto (una fracción no encuentra pareja exacta por mismo stockcode y customer_id), añade heurísticas y aporta poca precisión adicional sobre la opción simple.
Alternativas descartadas. Aparear con la venta original y restar (trabajo desproporcionado para precisión marginal) y descartar todas las cancelaciones (infla el revenue artificialmente).
Consecuencias visibles. En el siguiente bloque cuento las líneas de cancelación, calculo el revenue “bruto” (solo positivas) frente al neto (con cancelaciones incluidas) y muestro cuánto pierde el total por las devoluciones.
df_cliente["es_cancelacion"] = df_cliente["invoice"].str.startswith("C")n_cancelaciones = df_cliente["es_cancelacion"].sum()revenue_negativo = df_cliente.loc[df_cliente["es_cancelacion"], "importe"].sum()revenue_bruto = df_cliente.loc[~df_cliente["es_cancelacion"], "importe"].sum()revenue_neto = df_cliente["importe"].sum()print(f"Líneas de cancelación: {n_cancelaciones:,} "f"({n_cancelaciones/len(df_cliente)*100:.2f}% de filas con ID)")print(f"Revenue bruto (solo positivas): {revenue_bruto:,.2f}")print(f"Revenue neto (con cancelaciones): {revenue_neto:,.2f}")print(f"Reducción por cancelaciones: {-revenue_negativo:,.2f} "f"({-revenue_negativo/revenue_bruto*100:.2f}% del bruto)")
Líneas de cancelación: 18,744 (2.27% de filas con ID)
Revenue bruto (solo positivas): 17,743,429.18
Revenue neto (con cancelaciones): 16,648,292.39
Reducción por cancelaciones: 1,095,136.79 (6.17% del bruto)
Ventana de observación para RFM
El dataset cubre dos años. Para RFM hay que elegir una ventana.
ImportanteDecisión 3: ventana de observación para RFM
Decisión. RFM se calcula sobre los últimos 12 meses del dataset, ventana cerrada el 2011-12-09 (último día con datos completos). El cálculo de cohortes (sección 1.4) y los modelos del capítulo 6 siguen usando todo el histórico disponible.
Por qué. Doce meses son un ciclo estacional completo (incluye el pico de octubre y noviembre, que en este negocio es muy relevante), encaja con la convención que verás en cualquier herramienta de marketing automation y deja fuera el primer mes truncado del dataset. Es la elección por defecto razonable.
Alternativas descartadas. Usar todo el dataset (mezcla cohortes muy distintas y mete el truncamiento dentro del cálculo) y ventana de seis meses (demasiado corta para un negocio con cadencia de mayoreo de dos o tres meses; riesgo alto de etiquetar como “Lost” a clientes que están en su ciclo natural).
Consecuencias visibles. El siguiente bloque te enseña cuántos clientes tienen al menos una compra dentro de la ventana y cuántos quedan fuera (clientes con compras tempranas y ya inactivos).
FECHA_CORTE = pd.Timestamp("2011-12-09")VENTANA_INICIO = FECHA_CORTE - pd.Timedelta(days=365)mask_ventana = ( (df_cliente["invoice_date"] >= VENTANA_INICIO) & (df_cliente["invoice_date"] <= FECHA_CORTE + pd.Timedelta(days=1)))df_ventana = df_cliente[mask_ventana].copy()clientes_en_ventana = df_ventana["customer_id"].nunique()clientes_totales = df_cliente["customer_id"].nunique()print(f"Ventana RFM: {VENTANA_INICIO.date()} -> {FECHA_CORTE.date()}")print(f"Clientes con al menos una compra en ventana: {clientes_en_ventana:,} "f"de {clientes_totales:,} ({clientes_en_ventana/clientes_totales*100:.1f}%)")print(f"Clientes fuera de ventana (sólo cuentan para cohortes): "f"{clientes_totales - clientes_en_ventana:,}")
Ventana RFM: 2010-12-09 -> 2011-12-09
Clientes con al menos una compra en ventana: 4,307 de 5,942 (72.5%)
Clientes fuera de ventana (sólo cuentan para cohortes): 1,635
Definición de monetary value
Monetary tiene varias acepciones razonables. Te dejo aquí la coherente con la decisión 2 sobre cancelaciones.
ImportanteDecisión 4: cómo calcular monetary value
Decisión. El monetary value es la suma neta de quantity × price por cliente dentro de la ventana, incluyendo las cancelaciones con su signo negativo. No se aplica margen estimado.
Por qué. Es coherente con la decisión 2: si las cancelaciones se quedan como filas negativas, el monetary “limpio” es el neto. Además, no se introduce ninguna hipótesis adicional sobre margen, lo que mantiene el caso práctico sostenido por los datos crudos (y no por una cifra inventada). En el capítulo 6 sí discuto el paso de revenue a margen, pero como salvedad explícita.
Alternativas descartadas. Margen estimado con coste variable supuesto (pedagógicamente interesante pero introduce una cifra inventada que se arrastra a los caps. 6 y 7) e importe bruto sin restar cancelaciones (incoherente con la decisión 2).
Consecuencias visibles. Algunos clientes con cancelaciones grandes acaban con monetary muy bajo o, en casos extremos, negativo. El bloque siguiente cuenta cuántos.
# El cálculo de monetary se hace más abajo, en la sección de RFM, pero ya puedes mirar el efecto# agregado: total neto por cliente y cuántos acaban con M <= 0.m_por_cliente = df_ventana.groupby("customer_id")["importe"].sum()print(f"Clientes con monetary <= 0: {(m_por_cliente <=0).sum():,}")print(f"Clientes con monetary < 0: {(m_por_cliente <0).sum():,}")print(f"Monetary medio: {m_por_cliente.mean():,.2f}")print(f"Monetary mediano: {m_por_cliente.median():,.2f}")
Clientes con monetary <= 0: 48
Clientes con monetary < 0: 39
Monetary medio: 1,873.65
Monetary mediano: 648.69
Tabla transaccional consolidada
Tras las cuatro decisiones, tienes una tabla transaccional limpia y trazable. Esta es la base sobre la que se construyen las cohortes (1.4) y el RFM (1.5).
Una cohorte es un grupo de clientes captados en el mismo mes. La pregunta que respondes con cohortes es: ¿qué fracción de cada cohorte sigue activa al cabo de N meses? La respuesta, tabulada y representada como mapa de calor, te dice mucho sobre la estructura de retención de tu base.
Construyo la matriz de retención con dos pasos. Primero, asigno a cada cliente su cohorte (el mes de su primera compra). Después, cuento, para cada combinación cohorte-edad, cuántos clientes únicos tienen alguna compra en ese mes.
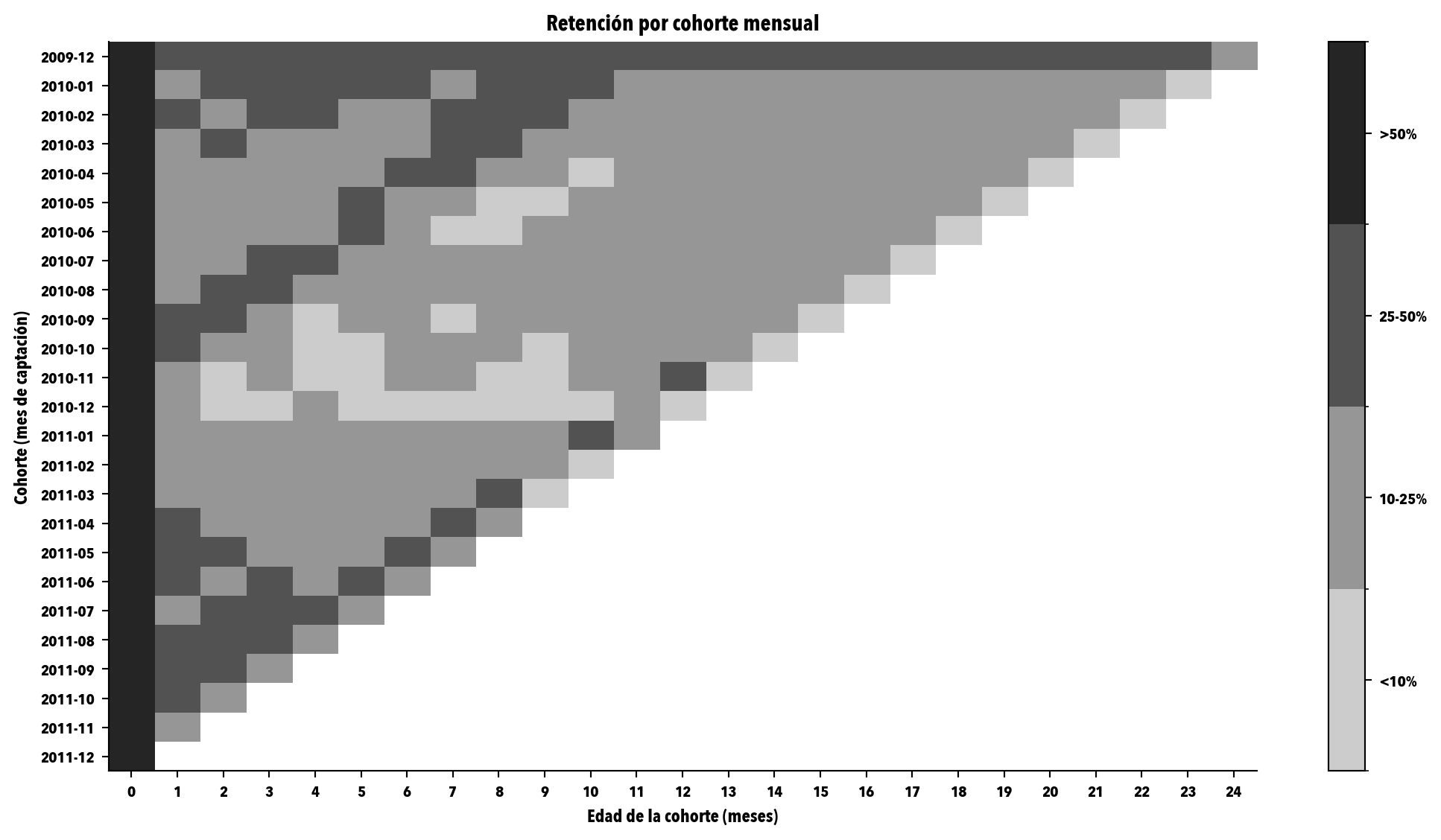
fig, ax = plt.subplots(figsize=(11, 6))# Bordes para la escala de 4 nivelesboundaries = [0.0001, 0.10, 0.25, 0.50, 1.01]norm = BoundaryNorm(boundaries, CMAP_GRISES.N)# NaN para celdas no observadasmasked = retencion.where(retencion >0, np.nan)im = ax.imshow(masked.values, aspect="auto", cmap=CMAP_GRISES, norm=norm)ax.set_yticks(range(len(retencion)))ax.set_yticklabels([str(c) for c in retencion.index])ax.set_xticks(range(retencion.shape[1]))ax.set_xticklabels([str(c) for c in retencion.columns])ax.set_xlabel("Edad de la cohorte (meses)")ax.set_ylabel("Cohorte (mes de captación)")ax.set_title("Retención por cohorte mensual")cbar = fig.colorbar(im, ax=ax, ticks=[0.05, 0.175, 0.375, 0.755])cbar.ax.set_yticklabels(["<10%", "10-25%", "25-50%", ">50%"])plt.tight_layout()plt.show()
Figura 2: Mapa de calor de retención por cohorte mensual sobre Online Retail II. Cada fila es la cohorte de captación, cada columna es la edad en meses. La intensidad codifica la fracción de la cohorte que sigue activa: gris claro para porcentajes bajos (<10%), gris oscuro para retenciones altas (>50%). Las celdas vacías corresponden a periodos aún no observados.
Tres cosas que conviene que leas en este mapa, y que en general miras en cualquier heatmap de cohortes:
Primero, la forma de la curva de retención. La columna 0 está al 100 % por construcción (todas las cohortes están vivas el mes en que las capturas). La columna 1 te enseña cuánto se cae en el primer mes, que en cualquier base no contractual madura es siempre una caída fuerte. Después, el ritmo de descenso se modera. Esa forma no es accidental: es la huella de la heterogeneidad de tu base, lo formalizo en el capítulo 6.
Segundo, la estabilidad cohorte a cohorte. Las filas inferiores son las cohortes nuevas, las superiores las viejas. Si las filas de abajo se “apagan” antes que las de arriba, algo ha cambiado: producto, canal de captación, competencia. En este dataset, mira si las cohortes de 2011 envejecen distinto que las de 2010.
Tercero, los escalones inexplicables. Si una columna entera del heatmap muestra una caída anómala (todas las cohortes pierden mucho cliente en la misma edad), suele apuntar a un evento exógeno: subida de precios, cambio de política, incidencia técnica. Si lo encuentras, no lo ignores; es información operativa con valor por sí misma.
RFM
Recordatorio del capítulo 5: RFM es retrospectivo por construcción. Las tres variables resumen el comportamiento observado del cliente; ninguna afirma nada sobre el futuro. Aquí construyo el RFM sobre la ventana de 12 meses definida en la decisión 3.
rfm = (df_ventana.groupby("customer_id") .agg(recency_dias=("invoice_date", lambda x: (FECHA_CORTE - x.max()).days), frequency=("invoice", "nunique"), monetary=("importe", "sum")) .reset_index())print(f"Clientes en el RFM: {len(rfm):,}")print(f"\nRecency (días desde última compra):")print(f" media={rfm['recency_dias'].mean():.1f}, mediana={rfm['recency_dias'].median():.0f}, "f"p90={rfm['recency_dias'].quantile(0.9):.0f}")print(f"\nFrequency (nº de facturas únicas en ventana):")print(f" media={rfm['frequency'].mean():.2f}, mediana={rfm['frequency'].median():.0f}, "f"p90={rfm['frequency'].quantile(0.9):.0f}")print(f"\nMonetary (importe neto en ventana):")print(f" media={rfm['monetary'].mean():.2f}, mediana={rfm['monetary'].median():.2f}, "f"p90={rfm['monetary'].quantile(0.9):.2f}")rfm.head()
Clientes en el RFM: 4,307
Recency (días desde última compra):
media=86.4, mediana=46, p90=252
Frequency (nº de facturas únicas en ventana):
media=4.97, mediana=3, p90=11
Monetary (importe neto en ventana):
media=1873.65, mediana=648.69, p90=3442.61
customer_id
recency_dias
frequency
monetary
0
12346
324
2
0.00
1
12347
1
6
3598.21
2
12348
74
4
1797.24
3
12349
17
1
1757.55
4
12350
309
1
334.40
A continuación, el scoring por quintiles. Para Recency, el quintil más alto (5) corresponde al cliente más reciente; para Frequency y Monetary, el más alto al que más compra. Empleo pd.qcut con rank(method="first") para evitar problemas de empates: en datasets con muchos clientes que compran exactamente una vez, los quintiles “limpios” pueden colapsar.
def quintil(serie: pd.Series, ascending: bool=True) -> pd.Series:"""Quintil 1-5. Si ascending=True, valor alto -> score alto.""" ranked = serie.rank(method="first", ascending=ascending)return pd.qcut(ranked, 5, labels=[1, 2, 3, 4, 5]).astype(int)# Para Recency: más reciente = menor recency_dias = score más altorfm["R"] = quintil(rfm["recency_dias"], ascending=False)rfm["F"] = quintil(rfm["frequency"], ascending=True)rfm["M"] = quintil(rfm["monetary"], ascending=True)def asignar_segmento(row: pd.Series) ->str: R, F, M = row["R"], row["F"], row["M"]if R >=4and F >=4and M >=4:return"Champions"if F >=4and M >=4and R ==3:return"Loyal Customers"if R >=4and F <=3and F >=2:return"Potential Loyalists"if R >=4and F ==1:return"New Customers"if R <=2and F >=4and M >=4:return"Can't Lose Them"if R <=2and F >=3:return"At Risk"if R <=2and F <=2and M <=2:return"Lost"return"Hibernating"rfm["segmento"] = rfm.apply(asignar_segmento, axis=1)rfm[["customer_id", "recency_dias", "frequency", "monetary", "R", "F", "M", "segmento"]].head(10)
Mira la concentración. En cualquier base no contractual real, el top de segmentos (Champions, Loyal Customers, Can’t Lose Them) concentra una fracción de revenue muy superior a su fracción de clientes; los Hibernating y Lost son una proporción enorme de clientes pero una contribución muy menor al revenue. Esa asimetría no es un defecto: es la estructura típica de una base de clientes, y es exactamente la razón por la que cualquier decisión de marketing necesita segmentación.
El “Champion eterno”: diagnóstico empírico
Te recordé en el capítulo 5 que el etiquetado “Champion” es retrospectivo y, por tanto, puede contener clientes que se fueron hace tiempo pero que la ventana de doce meses todavía cuenta. Voy a buscarlos empíricamente: dentro del segmento Champions, calculo el gap máximo entre dos compras consecutivas dentro de la ventana y marco como sospechosos a los que tienen ese gap muy por encima de la mediana. La intuición: un Champion auténtico tiene un patrón regular de compras, sin huecos largos. Un “Champion eterno” tiene compras concentradas al principio de la ventana y un agujero hacia el final.
champions_ids = rfm.loc[rfm["segmento"] =="Champions", "customer_id"].tolist()trans_champions = (df_ventana[df_ventana["customer_id"].isin(champions_ids)] .sort_values(["customer_id", "invoice_date"]))def gap_maximo_dias(g: pd.DataFrame) ->float:iflen(g) <2:return np.nan diffs = g["invoice_date"].diff().dt.days.dropna()returnfloat(diffs.max()) iflen(diffs) else np.nangaps = (trans_champions.groupby("customer_id")[["invoice_date"]] .apply(gap_maximo_dias) .reset_index(name="gap_max_dias") .dropna())mediana_gap = gaps["gap_max_dias"].median()umbral =max(mediana_gap *3, 60) # mínimo 60 días para evitar umbrales absurdossospechosos = gaps[gaps["gap_max_dias"] > umbral]print(f"Champions totales: {len(champions_ids):,}")print(f"Mediana del gap máximo entre compras (en días): {mediana_gap:.1f}")print(f"Umbral 'sospechoso' (3 x mediana, mínimo 60 días): {umbral:.0f}")print(f"Champions sospechosos de ser 'eternos': {len(sospechosos):,} "f"({len(sospechosos)/max(len(champions_ids),1)*100:.1f}% del segmento)")
Champions totales: 939
Mediana del gap máximo entre compras (en días): 81.0
Umbral 'sospechoso' (3 x mediana, mínimo 60 días): 243
Champions sospechosos de ser 'eternos': 15 (1.6% del segmento)
Si la cifra de sospechosos es pequeña, enhorabuena, tu base no contractual tiene Champions razonablemente activos; el etiquetado retrospectivo te está contando una historia coherente con la realidad. Si la cifra es grande, tienes un problema clásico de RFM: estás reteniendo etiquetas que la realidad ya ha desmentido. La solución no es ajustar el RFM (sigue siendo retrospectivo), es complementarlo con los modelos probabilísticos del capítulo 6, que estiman pAlive y te dejan ver a tiempo qué Champions ya han dejado de serlo.
Persistencia
La parte retrospectiva del caso termina aquí, pero las tablas que produce son la entrada de los caps. 6 y 7. Las dejo en materiales/cap05/outputs/ en formato parquet (rápido de cargar, conserva tipos, ocupa poco). Añado una pequeña ficha del dataset (CARD.md) que documenta las cuatro decisiones para que el cap. 6 la pueda citar sin recalcular nada.
transacciones_limpias.to_parquet(OUT_DIR /"transacciones_limpias.parquet", index=False)retencion.reset_index().to_parquet(OUT_DIR /"matriz_cohortes.parquet", index=False)rfm.to_parquet(OUT_DIR /"rfm_tabla.parquet", index=False)# Hash del fuente para trazabilidadh = hashlib.sha256()withopen(RAW_FILE, "rb") as f:for bloque initer(lambda: f.read(8192), b""): h.update(bloque)hash_xlsx = h.hexdigest()[:16]card =f"""# Ficha del dataset procesado**Generado:** {pd.Timestamp.now().strftime('%Y-%m-%d %H:%M:%S')}**Fuente:** Online Retail II (UCI ML Repository, id=502)**Hash sha256[:16] del .xlsx crudo:** `{hash_xlsx}`## Cifras agregadas- Líneas totales (con nulos): {len(df):,}- Líneas con Customer ID: {len(df_cliente):,}- Clientes únicos (con ID): {df_cliente['customer_id'].nunique():,}- Facturas únicas (con ID): {df_cliente['invoice'].nunique():,}- Rango temporal: {df['invoice_date'].min().date()} a {df['invoice_date'].max().date()}- Revenue neto total: {df_cliente['importe'].sum():,.2f}- Cancelaciones: {int(df_cliente['es_cancelacion'].sum()):,} líneas## Decisiones tomadas en el caso práctico1. **Customer ID nulos:** excluidos para análisis de cliente, conservados en auditoría preliminar.2. **Cancelaciones:** mantenidas como filas independientes con `Quantity` e importe negativos.3. **Ventana RFM:** 12 meses cerrando 2011-12-09.4. **Monetary value:** importe neto = sum(quantity * price), incluye cancelaciones con su signo.## Artefactos persistidos- `transacciones_limpias.parquet`: tabla transaccional con ID, alimenta caps. 6 y 7.- `matriz_cohortes.parquet`: matriz cohorte x edad con fracción de retención.- `rfm_tabla.parquet`: una fila por cliente con R, F, M, scores y segmento canónico."""(OUT_DIR /"CARD.md").write_text(card, encoding="utf-8")print("Artefactos persistidos en materiales/cap05/outputs/:")for f insorted(OUT_DIR.iterdir()):print(f" {f.name:35s}{f.stat().st_size/1024:>8.1f} KB")
Hasta aquí, has hecho lo que pide cualquier proyecto serio de CLV en su primera fase: auditar la base, tomar cuatro decisiones de limpieza, mirar cohortes y construir el RFM. Las tres tablas que persististe en 1.6 son el suelo retrospectivo del caso.
Lo que viene a continuación es el lado predictivo del capítulo 6 y la validación del capítulo 7, en el orden que cualquier análisis defendible exige: construir, validar y, sólo si pasa la validación, accionar. En 1.8 vas a calibrar BG/NBD y Gamma-Gamma sobre las transacciones limpias, vas a generar predicciones por cliente (pAlive, número esperado de compras, valor esperado hacia adelante a 12 meses) y vas a recuperar el caso del “Champion eterno” para ver qué dice el modelo. En 1.9 vas a someter ese modelo a la batería de validaciones del cap. 7: holdout temporal, predicciones agregadas, calibration plot, decile analysis, lift sobre RFM y, finalmente, el ejercicio gerencial del top 100. Y, sólo si el modelo sale airoso, en 1.10 le darás forma gerencial: quintiles de valor, proyecciones a varios horizontes y dos tasas de descuento en paralelo, para responder a la pregunta que cualquier dirección quiere oír («¿cuánto vale cada segmento de mi base y durante cuánto tiempo?»).
Las decisiones nuevas, también con su bloque fijo de decisión / por qué / alternativas / consecuencias visibles, son tres: el corte temporal calibración / holdout, qué hacer con las cancelaciones de cara al ajuste y qué familia de modelo eliges para este caso.
Modelado predictivo: BG/NBD y Gamma-Gamma
Decisión 5: corte temporal calibración / holdout
NotaDecisión 5: corte calibración / holdout
Decisión. Corte el 1 de junio de 2011: 18 meses de calibración (2009-12-01 a 2011-05-31) y poco más de 6 meses de holdout (2011-06-01 a 2011-12-09).
Por qué. Quiero un holdout que cubra al menos un par de meses navideños completos (la huella del mayorista de la que ya hablamos en 1.1), porque sin ellos la validación deja fuera el comportamiento más distintivo de la base.
Alternativas descartadas. Corte ciego 80/20 sobre la duración (deja el holdout en plena temporada baja y mete el navideño de 2010 en calibración pero el de 2011 fuera). Corte 70/30 (deja la calibración demasiado corta para clientes con frecuencia baja).
Consecuencias visibles. Cualquier cliente que aparezca por primera vez después del 1 de junio de 2011 no entra en el modelo; los retomamos en 1.10.6 cuando hablemos de cómo accionar el análisis sobre clientes nuevos en general.
import warningswarnings.filterwarnings("ignore") # lifetimes lanza algunos FutureWarning de scipy# Cargamos los artefactos de la sección de persistenciatransacciones = pd.read_parquet(OUT_DIR /"transacciones_limpias.parquet")rfm = pd.read_parquet(OUT_DIR /"rfm_tabla.parquet")# Asegurar tipostransacciones["invoice_date"] = pd.to_datetime(transacciones["invoice_date"])transacciones["customer_id"] = transacciones["customer_id"].astype(str)rfm["customer_id"] = rfm["customer_id"].astype(str)# Corte temporalfecha_corte_cal = pd.Timestamp("2011-06-01")fecha_fin_obs = transacciones["invoice_date"].max()print(f"Inicio del histórico: {transacciones['invoice_date'].min().date()}")print(f"Cierre de calibración: {fecha_corte_cal.date()}")print(f"Fin de observación: {fecha_fin_obs.date()}")print(f"Duración calibración: {(fecha_corte_cal - transacciones['invoice_date'].min()).days} días")print(f"Duración holdout: {(fecha_fin_obs - fecha_corte_cal).days} días")
Inicio del histórico: 2009-12-01
Cierre de calibración: 2011-06-01
Fin de observación: 2011-12-09
Duración calibración: 546 días
Duración holdout: 191 días
Decisión 6: cancelaciones en el ajuste
NotaDecisión 6: cancelaciones en el ajuste
Decisión. Filtrar las cancelaciones (importe negativo) antes de calibrar BG/NBD. Para Gamma-Gamma uso el monetary_value neto medio, calculado sobre las transacciones positivas únicamente.
Por qué. BG/NBD modela un proceso de compras repetidas; una cancelación no es una nueva compra, es la anulación de una previa. Si la dejo dentro, sobreestimo la frecuencia.
Alternativas descartadas. Aparear cancelaciones con la venta original y trabajar con cestas netas (alto riesgo de errores de matching en este dataset, donde los IDs no son consistentes en cancelaciones). Conservarlas con signo (rompe el supuesto de proceso de conteo no negativo de BG/NBD).
Consecuencias visibles. Pierdo unas 18.700 líneas (~2,3 %) en el ajuste. La pérdida es uniforme entre clientes con alta y baja frecuencia, así que no introduce sesgos sistemáticos.
# Filtramos para el ajustetrans_pos = transacciones[transacciones["importe"] >0].copy()print(f"Transacciones totales: {len(transacciones):,}")print(f"Transacciones positivas: {len(trans_pos):,}")print(f"Cancelaciones excluidas: {(transacciones['importe'] <=0).sum():,}")print(f"Clientes con alguna positiva: {trans_pos['customer_id'].nunique():,}")
from lifetimes.utils import calibration_and_holdout_datacal_hold = calibration_and_holdout_data( trans_pos, customer_id_col="customer_id", datetime_col="invoice_date", monetary_value_col="importe", calibration_period_end=fecha_corte_cal, observation_period_end=fecha_fin_obs, freq="D")print(f"Clientes en summary calibración/holdout: {len(cal_hold):,}")print(f"Frecuencia media (calibración): {cal_hold['frequency_cal'].mean():.2f}")print(f"Recencia media (días): {cal_hold['recency_cal'].mean():.1f}")print(f"Antigüedad T media (días): {cal_hold['T_cal'].mean():.1f}")print(f"Ticket medio (calibración): {cal_hold['monetary_value_cal'].mean():.2f}")
Clientes en summary calibración/holdout: 4,933
Frecuencia media (calibración): 3.68
Recencia media (días): 188.5
Antigüedad T media (días): 358.2
Ticket medio (calibración): 281.42
Decisión 7: BG/NBD como modelo principal
NotaDecisión 7: BG/NBD como modelo principal (con Pareto/NBD de control)
Decisión. Calibro BG/NBD como modelo principal. Pareto/NBD entra solo como control diagnóstico al final.
Por qué. El caso es no contractual (cap. 5). La frecuencia media de compra es razonablemente alta (>3 compras en calibración para los clientes activos), el patrón es estable mes a mes (excepto el navideño previsto) y BG/NBD tiene mejor estabilidad numérica y rapidez. Es la elección estándar de la literatura para este tipo de retailer.
Alternativas descartadas. Solo Pareto/NBD (más lento sin aporte significativo aquí). Modelo de ML (no aporta valor para datos de este tamaño y este horizonte; sí podría aportar si tuviéramos features adicionales tipo categoría preferida, canal o sesiones web).
Consecuencias visibles. El ajuste se hace en segundos. Voy a verificar en 1.9 que la calibración es defendible antes de usar el modelo para nada más.
Diagnóstico previo a Gamma-Gamma: correlación frecuencia–ticket
# Gamma-Gamma exige independencia entre frecuencia y ticket mediogg_check = cal_hold[(cal_hold["frequency_cal"] >0) & (cal_hold["monetary_value_cal"] >0)].copy()corr_pearson = gg_check["frequency_cal"].corr(gg_check["monetary_value_cal"])corr_spearman = gg_check["frequency_cal"].corr(gg_check["monetary_value_cal"], method="spearman")print(f"Clientes válidos para Gamma-Gamma: {len(gg_check):,}")print(f"Correlación Pearson frecuencia-ticket: {corr_pearson:.4f}")print(f"Correlación Spearman frecuencia-ticket: {corr_spearman:.4f}")
Las correlaciones cercanas a cero (que es lo que se ve aquí) validan empíricamente el supuesto de independencia de Gamma-Gamma. Si vieras correlaciones de 0,2 o más en valor absoluto, sería momento de plantearte alternativas (ver la discusión del cap. 6 sobre híbridos).
Ajuste de BG/NBD
from lifetimes import BetaGeoFitterbgf = BetaGeoFitter(penalizer_coef=0.01)bgf.fit(cal_hold["frequency_cal"], cal_hold["recency_cal"], cal_hold["T_cal"])print("Parámetros BG/NBD calibrados:")for k, v in bgf.params_.items():print(f" {k:6s} = {v:.4f}")print(f"\nLog-likelihood: {bgf._negative_log_likelihood_ *-1:.2f}")
Parámetros BG/NBD calibrados:
r = 0.6667
alpha = 64.7282
a = 0.0472
b = 0.5703
Log-likelihood: 4.37
Ajuste de Gamma-Gamma
from lifetimes import GammaGammaFitterggf = GammaGammaFitter(penalizer_coef=0.01)ggf.fit(gg_check["frequency_cal"], gg_check["monetary_value_cal"])print("Parámetros Gamma-Gamma calibrados:")for k, v in ggf.params_.items():print(f" {k:6s} = {v:.4f}")
Parámetros Gamma-Gamma calibrados:
p = 3.7791
q = 0.3336
v = 3.6737
Predicciones por cliente
# pAlive: probabilidad de que el cliente siga vivo a fecha de cierre de calibraciónpalive = bgf.conditional_probability_alive( cal_hold["frequency_cal"], cal_hold["recency_cal"], cal_hold["T_cal"])# Número esperado de compras en los próximos 180 días (escala del holdout)exp_compras_180 = bgf.conditional_expected_number_of_purchases_up_to_time(180, cal_hold["frequency_cal"], cal_hold["recency_cal"], cal_hold["T_cal"])# Ticket medio esperado (Gamma-Gamma): definido solo para frequency > 0exp_ticket = pd.Series(index=cal_hold.index, dtype=float)mask_freq_pos = cal_hold["frequency_cal"] >0exp_ticket.loc[mask_freq_pos] = ggf.conditional_expected_average_profit( cal_hold.loc[mask_freq_pos, "frequency_cal"], cal_hold.loc[mask_freq_pos, "monetary_value_cal"])# Para clientes con frecuencia 0 en calibración, el ticket esperado es la media poblacionalexp_ticket.loc[~mask_freq_pos] = gg_check["monetary_value_cal"].mean()# Valor esperado hacia adelante a 12 meses, con tasa de descuento mensual del 1 %.# Es la cifra forward-looking del modelo; OJO, no es el CLV del libro (cap. 4),# que se ancla en el día 0 de la relación y no incorpora la historia.valor_esperado_12m = pd.Series(index=cal_hold.index, dtype=float)valor_esperado_12m.loc[mask_freq_pos] = ggf.customer_lifetime_value( bgf, cal_hold.loc[mask_freq_pos, "frequency_cal"], cal_hold.loc[mask_freq_pos, "recency_cal"], cal_hold.loc[mask_freq_pos, "T_cal"], cal_hold.loc[mask_freq_pos, "monetary_value_cal"], time=12, # meses freq="D", # los inputs están en días discount_rate=0.01)valor_esperado_12m.loc[~mask_freq_pos] =0.0# Consolidaciónpredicciones = pd.DataFrame({"customer_id": cal_hold.index.astype(str),"frequency_cal": cal_hold["frequency_cal"].values,"recency_cal": cal_hold["recency_cal"].values,"T_cal": cal_hold["T_cal"].values,"monetary_value_cal": cal_hold["monetary_value_cal"].values,"pAlive": np.asarray(palive),"exp_compras_180d": np.asarray(exp_compras_180),"exp_ticket": exp_ticket.values,"valor_esperado_12m": valor_esperado_12m.values,"frequency_holdout": cal_hold["frequency_holdout"].values,"monetary_value_holdout": cal_hold["monetary_value_holdout"].values,"duration_holdout": cal_hold["duration_holdout"].values})resumen = predicciones[["pAlive", "exp_compras_180d", "exp_ticket", "valor_esperado_12m"]].describe()print(resumen.round(3).to_string())
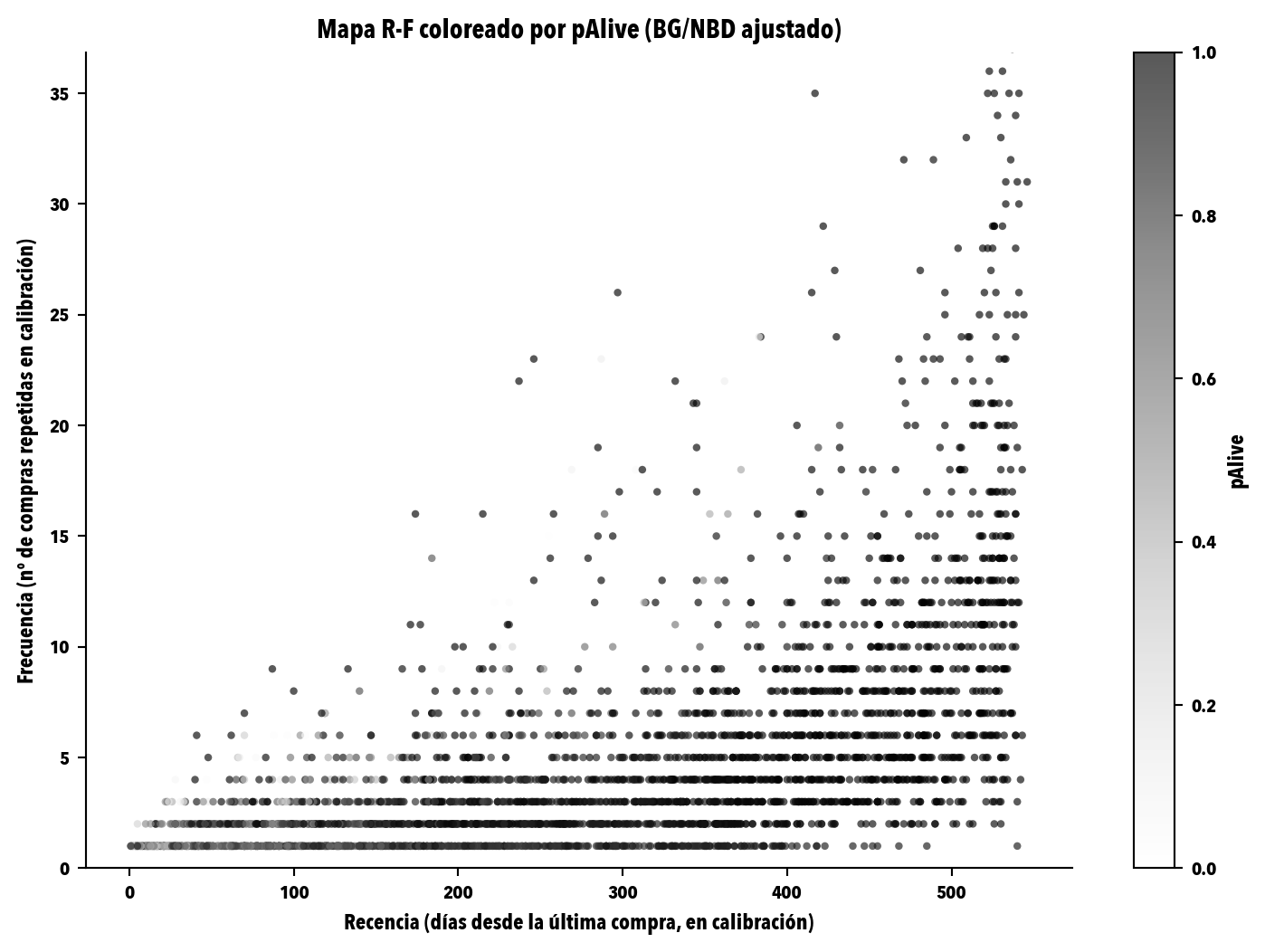
Esta es la misma figura que viste en el capítulo 6 del libro (Figura 3): el mapa que enseña visualmente cómo dos clientes con la misma recencia pueden tener pAlive radicalmente distintos según su frecuencia histórica.
fig, ax = plt.subplots(figsize=(7.8, 5.6))datos_plot = predicciones[predicciones["frequency_cal"] >0].copy()sc = ax.scatter( datos_plot["recency_cal"], datos_plot["frequency_cal"], c=datos_plot["pAlive"], cmap="Greys", s=10, alpha=0.65, vmin=0.0, vmax=1.0, edgecolor="none")ax.set_xlabel("Recencia (días desde la última compra, en calibración)")ax.set_ylabel("Frecuencia (nº de compras repetidas en calibración)")ax.set_title("Mapa R-F coloreado por pAlive (BG/NBD ajustado)")cbar = plt.colorbar(sc, ax=ax, label="pAlive")ax.set_ylim(0, min(datos_plot["frequency_cal"].quantile(0.99), 60))plt.tight_layout()# Esta figura es la única que el libro toma del caso. Se persiste aquí, dentro# del proyecto del caso, y se "promueve" al libro vía scripts/sync_figures.sh.fig_path = Path("figures/cap06_mapa_rf_palive.svg")fig_path.parent.mkdir(parents=True, exist_ok=True)plt.savefig(fig_path, bbox_inches="tight")plt.show()
Figura 3: Mapa R-F (recencia × frecuencia) coloreado por pAlive sobre Online Retail II. Cada punto es un cliente. El tono codifica la pAlive del BG/NBD: gris oscuro para pAlive alta (cliente con alta probabilidad de seguir activo), gris claro para pAlive baja. La diagonal sutil que se aprecia es la firma del modelo: para una recencia dada, los clientes con frecuencia alta tienen pAlive menor porque su silencio es más anómalo.
El “Champion eterno” revisitado
En 1.5 detectaste empíricamente, a partir del gap máximo entre compras, un grupo de Champions sospechosos. Aquí cruzas esa lista con la pAlive del modelo BG/NBD para ver si el modelo independientemente los identifica como menos vivos que el resto.
champions_ids = rfm.loc[rfm["segmento"] =="Champions", "customer_id"].astype(str).tolist()champions_pred = predicciones[predicciones["customer_id"].isin(champions_ids)].copy()print(f"Champions según RFM (segmentación retrospectiva): {len(champions_ids):,}")print(f"Champions con predicción disponible: {len(champions_pred):,}")print(f"\npAlive de los Champions:")print(champions_pred["pAlive"].describe().round(3).to_string())print(f"\nChampions con pAlive < 0.2 (probables 'eternos' según el modelo): "f"{(champions_pred['pAlive'] <0.2).sum():,} "f"({(champions_pred['pAlive'] <0.2).mean()*100:.1f}%)")print(f"Champions con pAlive < 0.5: "f"{(champions_pred['pAlive'] <0.5).sum():,} "f"({(champions_pred['pAlive'] <0.5).mean()*100:.1f}%)")
Champions según RFM (segmentación retrospectiva): 939
Champions con predicción disponible: 830
pAlive de los Champions:
count 830.000
mean 0.965
std 0.073
min 0.076
25% 0.968
50% 0.989
75% 0.995
max 1.000
Champions con pAlive < 0.2 (probables 'eternos' según el modelo): 2 (0.2%)
Champions con pAlive < 0.5: 2 (0.2%)
Una pAlive baja sobre clientes que RFM marca como Champions es exactamente la huella de un “Champion eterno”: el etiquetado retrospectivo seguía clasificándolos como mejores clientes, pero el modelo, condicional a la frecuencia y la antigüedad, ya estaba diciendo “ojo, este lleva demasiado callado para su patrón normal”. El cap. 7 retomará este grupo en el ejercicio gerencial del top 100.
Antes de usar el modelo para nada, hay que ponerlo a prueba. Ese es el orden de cualquier análisis defendible: construir, validar y, si pasa, accionar. Si saltas la validación y vas directo a la acción, lo que llega a tu comité de dirección es una cifra con dos decimales y la hipótesis silenciosa de que «esto funciona». Esta sección hace exactamente lo contrario: somete el BG/NBD ajustado a la batería del capítulo 7 (cuatro validaciones estadísticas y un ejercicio gerencial sobre el top 100, modelo vs RFM) antes de que en 1.10 montemos los segmentos de valor sobre el modelo ya validado.
# Recargamos los artefactos relevantes (predicciones del modelado y rfm de la persistencia)# para que esta validación pueda ejecutarse de forma independiente.predicciones = pd.read_parquet(OUT_DIR /"predicciones_clv.parquet")predicciones["customer_id"] = predicciones["customer_id"].astype(str)rfm = pd.read_parquet(OUT_DIR /"rfm_tabla.parquet")rfm["customer_id"] = rfm["customer_id"].astype(str)# Duración del holdout (todos los clientes tienen la misma porque el corte es absoluto)dur_holdout =float(predicciones["duration_holdout"].iloc[0])print(f"Duración del holdout: {dur_holdout:.0f} días ({dur_holdout/30:.1f} meses aprox.)")
Duración del holdout: 191 días (6.4 meses aprox.)
Validación 1: predicciones agregadas
# El modelo predice E[X(180)]; el holdout dura ~190 días. Reescalamos linealmente.factor = dur_holdout /180predicciones["exp_compras_ajustado"] = predicciones["exp_compras_180d"] * factortotal_predicho = predicciones["exp_compras_ajustado"].sum()total_observado = predicciones["frequency_holdout"].sum()print(f"Predicción agregada de compras (ajustada al holdout): {total_predicho:,.0f}")print(f"Compras observadas en el holdout: {total_observado:,.0f}")print(f"Ratio predicha / observada: {total_predicho/max(total_observado,1):.3f}")
Predicción agregada de compras (ajustada al holdout): 7,592
Compras observadas en el holdout: 8,136
Ratio predicha / observada: 0.933
Una ratio entre 0,90 y 1,10 indica que la predicción agregada es razonablemente fiel. Por encima de 1,10 el modelo sobreestima; por debajo de 0,90 subestima. En cualquier caso, el agregado es solo el primer escalón.
Validación 2: calibration plot por decil
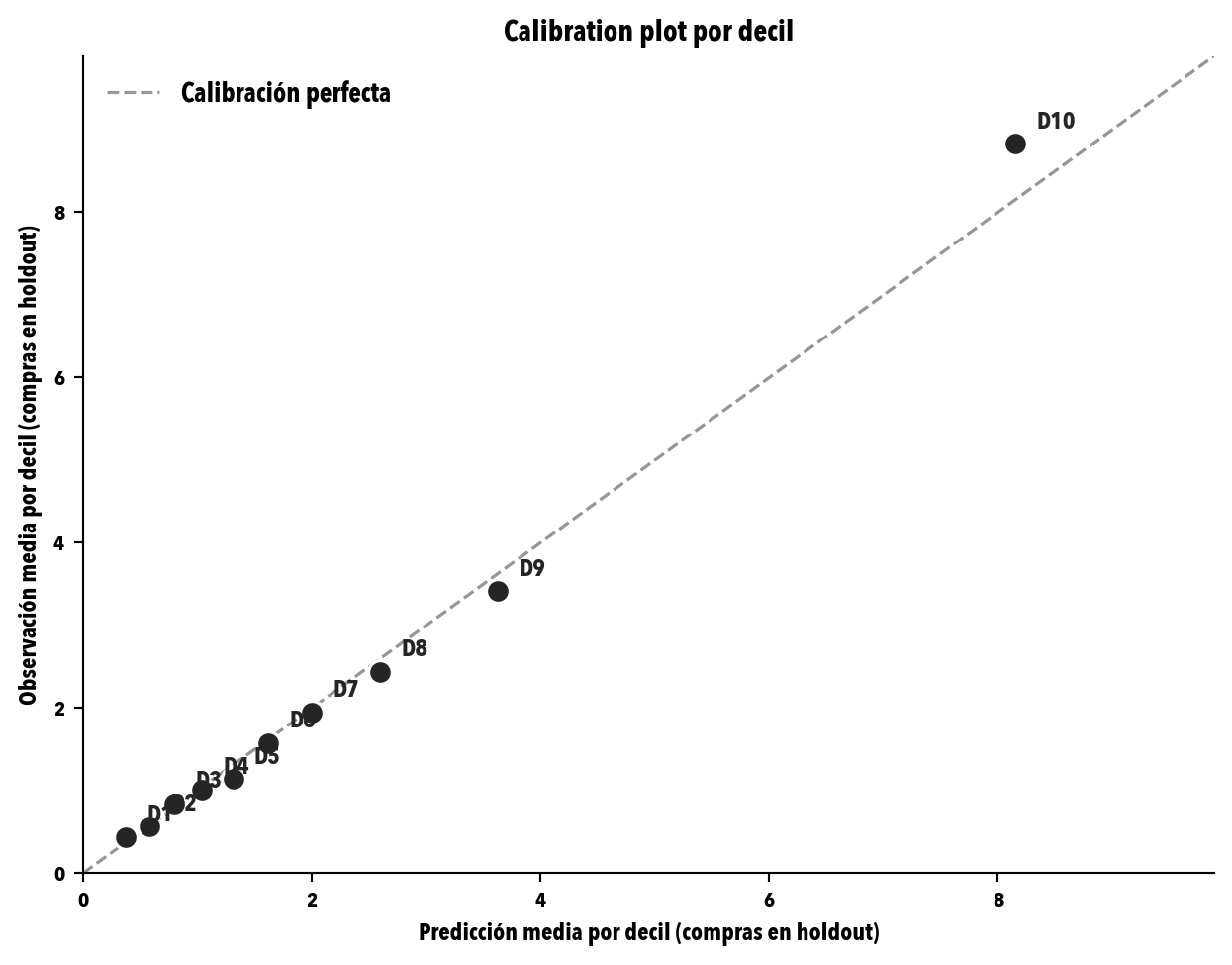
datos_cal = predicciones[predicciones["frequency_cal"] >0].copy()datos_cal["decil"] = pd.qcut(datos_cal["exp_compras_ajustado"], q=10, labels=False, duplicates="drop")deciles = datos_cal.groupby("decil").agg( predicho_medio=("exp_compras_ajustado", "mean"), observado_medio=("frequency_holdout", "mean"), n=("customer_id", "size")).reset_index()fig, ax = plt.subplots(figsize=(6.6, 5.2))max_val =max(deciles["predicho_medio"].max(), deciles["observado_medio"].max()) *1.12ax.plot([0, max_val], [0, max_val], "--", color="#969696", linewidth=1.2, label="Calibración perfecta")ax.scatter(deciles["predicho_medio"], deciles["observado_medio"], s=80, color="#252525", edgecolor="white", linewidth=1.2, zorder=3)for _, r in deciles.iterrows(): ax.annotate(f"D{int(r['decil'])+1}", xy=(r["predicho_medio"], r["observado_medio"]), xytext=(8, 6), textcoords="offset points", fontsize=9, color="#252525")ax.set_xlabel("Predicción media por decil (compras en holdout)")ax.set_ylabel("Observación media por decil (compras en holdout)")ax.set_title("Calibration plot por decil")ax.legend(loc="upper left", frameon=False)ax.set_xlim(0, max_val)ax.set_ylim(0, max_val)plt.tight_layout()plt.savefig(OUT_DIR /"calibration_plot.svg", bbox_inches="tight")plt.show()
Figura 4: Calibration plot por decil. Cada punto es un decil de predicción del BG/NBD. El eje X es la predicción media (ajustada a la duración del holdout); el Y es la observación media. La diagonal punteada es la calibración perfecta. Desviaciones sistemáticas indican mala calibración.
Validación 3: decile analysis
print("Comportamiento observado en el holdout por decil de predicción:")print(deciles.round(3).to_string(index=False))obs_secuencia = deciles["observado_medio"].valueses_monotono =all(obs_secuencia[i] <= obs_secuencia[i+1] for i inrange(len(obs_secuencia)-1))print(f"\n¿La secuencia observada por decil es monótona creciente? {es_monotono}")print(f"Ratio D10 / D1: {obs_secuencia[-1]/max(obs_secuencia[0], 0.001):.2f}x")
Comportamiento observado en el holdout por decil de predicción:
decil predicho_medio observado_medio n
0 0.374 0.437 332
1 0.581 0.568 331
2 0.797 0.846 332
3 1.038 1.009 331
4 1.312 1.139 332
5 1.623 1.577 331
6 2.001 1.943 331
7 2.594 2.434 332
8 3.627 3.414 331
9 8.152 8.828 332
¿La secuencia observada por decil es monótona creciente? True
Ratio D10 / D1: 20.21x
Una ratio D10/D1 alta (idealmente >5x para discriminación buena) significa que el modelo separa bien a los valiosos de los poco valiosos. Una ratio cercana a 1 indica que el modelo es esencialmente ruido.
Validación 4: lift sobre el baseline RFM
# Cruzamos predicciones con RFM. Las columnas son R, F, M (quintiles 1-5) y "segmento".rfm_aux = rfm[["customer_id", "R", "F", "M", "segmento"]].copy()combined = rfm_aux.merge(predicciones, on="customer_id", how="inner")combined["rfm_score_agregado"] = combined["R"] + combined["F"] + combined["M"]N =100# Top N por modelo (valor esperado a 12 meses) y por RFM (suma de scores)top_modelo = combined.nlargest(N, "valor_esperado_12m")top_rfm = combined.nlargest(N, "rfm_score_agregado")# Comportamiento observado en el holdout: nº de comprascompras_top_modelo = top_modelo["frequency_holdout"].sum()compras_top_rfm = top_rfm["frequency_holdout"].sum()compras_aleatorio_esperado = combined["frequency_holdout"].mean() * N# Ingresos observados en el holdoutingr_top_modelo = top_modelo["monetary_value_holdout"].fillna(0).multiply(top_modelo["frequency_holdout"]).sum()ingr_top_rfm = top_rfm["monetary_value_holdout"].fillna(0).multiply(top_rfm["frequency_holdout"]).sum()print(f"Top {N} - compras observadas en holdout:")print(f" Modelo (valor esperado a 12m): {compras_top_modelo:,.0f}")print(f" RFM (score): {compras_top_rfm:,.0f}")print(f" Aleatorio: {compras_aleatorio_esperado:,.0f}")print(f"\nLift modelo vs aleatorio: {compras_top_modelo/max(compras_aleatorio_esperado, 0.001):.2f}x")print(f"Lift modelo vs RFM: {compras_top_modelo/max(compras_top_rfm, 0.001):.2f}x")
Top 100 - compras observadas en holdout:
Modelo (valor esperado a 12m): 1,270
RFM (score): 985
Aleatorio: 242
Lift modelo vs aleatorio: 5.25x
Lift modelo vs RFM: 1.29x
El ejercicio gerencial del top 100
ids_modelo =set(top_modelo["customer_id"])ids_rfm =set(top_rfm["customer_id"])I = ids_modelo & ids_rfm # intersecciónM = ids_modelo - ids_rfm # solo en modeloR = ids_rfm - ids_modelo # solo en RFMprint(f"=== Top {N}: consenso y disidencias ===")print(f"Intersección (I): {len(I):3d} clientes → consenso modelo + RFM")print(f"Solo modelo (M): {len(M):3d} clientes → modelo rescata, RFM no veía")print(f"Solo RFM (R): {len(R):3d} clientes → RFM mantiene, modelo descarta")print(f"\nTasa de coincidencia (overlap): {len(I)/N:.1%}")
=== Top 100: consenso y disidencias ===
Intersección (I): 26 clientes → consenso modelo + RFM
Solo modelo (M): 74 clientes → modelo rescata, RFM no veía
Solo RFM (R): 74 clientes → RFM mantiene, modelo descarta
Tasa de coincidencia (overlap): 26.0%
df_I = combined[combined["customer_id"].isin(I)]df_M = combined[combined["customer_id"].isin(M)]df_R = combined[combined["customer_id"].isin(R)]comp = pd.DataFrame({"Intersección (I)": df_I[["frequency_cal", "recency_cal", "pAlive", "valor_esperado_12m", "frequency_holdout"]].mean(),"Solo modelo (M)": df_M[["frequency_cal", "recency_cal", "pAlive", "valor_esperado_12m", "frequency_holdout"]].mean(),"Solo RFM (R)": df_R[["frequency_cal", "recency_cal", "pAlive", "valor_esperado_12m", "frequency_holdout"]].mean()}).round(2)print("Perfil medio de cada grupo (calibración + observado en holdout):")print(comp.to_string())print(f"\nCompras observadas en holdout, por grupo:")print(f" Intersección (I): {df_I['frequency_holdout'].sum():,.0f}")print(f" Solo modelo (M): {df_M['frequency_holdout'].sum():,.0f}")print(f" Solo RFM (R): {df_R['frequency_holdout'].sum():,.0f}")
Perfil medio de cada grupo (calibración + observado en holdout):
Intersección (I) Solo modelo (M) Solo RFM (R)
frequency_cal 37.12 31.01 13.61
recency_cal 439.31 453.80 405.32
pAlive 0.99 0.98 0.98
valor_esperado_12m 23587.35 26269.31 3566.39
frequency_holdout 15.42 11.74 7.89
Compras observadas en holdout, por grupo:
Intersección (I): 401
Solo modelo (M): 869
Solo RFM (R): 584
La decisión gerencial
Mirando las cifras, tres lecturas se imponen:
Intersección (I). Donde modelo y RFM coinciden no hay debate. Tu equipo de retención debe contactar a estos clientes sin discusión. El comportamiento observado en el holdout suele confirmar que son los más valiosos.
Solo modelo (M). Los rescatados por pAlive. Mira la fila “recency_cal”: en general suelen tener recencias más altas que la intersección, lo que les ha sacado del top de RFM. El modelo dice que su patrón histórico hace ese silencio normal y, por eso, los mantiene en el top. Si en el holdout su comportamiento medio se acerca al de la intersección, el modelo está acertando. Si se acerca al de “Solo RFM (R)”, el modelo está sobrestimando.
Solo RFM (R). Los “Champion eternos” que el modelo descarta. Compraron mucho, lo hicieron recientemente para RFM (porque la ventana de 12 meses captura sus compras antiguas), pero su pAlive es baja. Si en el holdout su comportamiento medio es bajo, el modelo está acertando y RFM está atrapado en su carácter retrospectivo. Si su comportamiento medio es alto, hay una salvedad operativa a registrar.
Tu decisión, leyendo la tabla anterior, tiene tres opciones limpias:
Sustituir RFM por modelo. Si el lift es claramente >1,5x y la intersección es razonable (50 % o más), justificable.
Mantener RFM y enriquecerlo con pAlive. Para los Champions de RFM, exiges pAlive > umbral antes de contactar. Es un híbrido conservador.
Mantener ambos en paralelo durante un periodo. Lo más sensato si vas a hacer un experimento A/B controlado en el cap. 12.
Cualquiera de las tres es defendible. Lo que no lo es: ignorar la diferencia. Si el modelo ha pasado las cuatro validaciones estadísticas y el ejercicio gerencial sin estridencias, ya tienes permiso para usarlo en serio: la sección 1.10 lo coge y lo convierte en una tabla de segmentos accionable.
Segmentos de valor: del modelo a la decisión
Has dejado el modelo bien atado en 1.9: la predicción agregada cuadra, los deciles ordenan razonablemente el comportamiento futuro y el lift sobre RFM es lo bastante claro como para tomar el modelo en serio. Toca, ahora sí, accionarlo. Hasta aquí tienes las cifras de cada cliente por separado (pAlive, número esperado de compras, ticket esperado, valor esperado a 12 meses), pero ningún comité de dirección quiere mirar una tabla de cuatro mil filas. Lo que quiere ver, y con razón, es una tabla pequeña que conteste a la pregunta directa: «¿cuántos clientes tengo en cada bandeja de valor, qué se espera de ellos y durante cuánto tiempo?». Esta sección monta esa tabla.
Antes de escribir una línea de código, conviene que te recuerde algo que repito a lo largo del libro: cualquier cifra de valor a futuro depende de un puñado de hipótesis, y la diferencia entre un análisis defendible y una cifra inventada en una hoja de cálculo es declarar esas hipótesis a la cara, no esconderlas detrás de un decimal. Así que las pongo todas sobre la mesa antes de que aparezca el primer número.
TipParámetros del cálculo, declarados a la cara
Modelo subyacente. BG/NBD (frecuencia y abandono) + Gamma-Gamma (ticket esperado), calibrados en 1.8 sobre los 18 meses de calibración y validados en 1.9.
Definición de monetary. Importe neto = quantity × price, incluyendo cancelaciones con su signo negativo (decisión 4 de 1.2). No se aplica margen estimado: trabajamos con revenue, no con beneficio.
Horizontes proyectados. 12, 24, 36 y 60 meses. El de 60 meses no es una promesa de permanencia; es el horizonte largo que uso como denominador para el “horizonte al 90 %” (más abajo).
Tasa de descuento. Dos en paralelo: 1,00 % mensual (≈12,68 % anual, base, coherente con 1.8) y 0,75 % mensual (≈9,38 % anual, alternativa más conservadora). Trabajar con dos tasas no es un alarde de prudencia: es la única forma honesta de que veas cuánto pesa la elección de tasa en el resultado final.
Horizonte al 90 %. Para cada cliente, el menor número de meses en el que el valor descontado acumulado alcanza el 90 % del valor descontado a 60 meses (con la tasa base). No es la vida residual del cliente en sentido teórico (BG/NBD no la entrega limpia); es un proxy interpretable de “permanencia”: cuánto tarda el modelo en concentrar la mayor parte del valor que espera de ese cliente.
Agrupación. Quintiles por valor esperado a 12 meses (tasa base), construidos sobre los clientes con frecuencia repetida (>0) en calibración. Los clientes con un único touchpoint en calibración van a un grupo aparte (“Sin compras repetidas”). Se añade una fila adicional Top 100 con la cabecera absoluta del ranking, que es la cifra que un director comercial usa de verdad para asignar presupuesto.
Proyección multi-horizonte y multi-tasa
Empiezo proyectando, mes a mes, las compras esperadas de cada cliente hasta los 60 meses. A partir de esa senda mensual de compras, multiplicada por el ticket esperado y descontada con cada una de las dos tasas, obtengo el valor descontado acumulado a cualquier horizonte. Es la mecánica que lifetimes.GammaGammaFitter.customer_lifetime_value ya hace internamente para un horizonte fijo; aquí la abro por debajo para tener toda la senda y poder calcular el horizonte al 90 % sin volver a llamar al modelo.
# Tasas de descuento (mensuales) y horizontesTASA_BASE =0.01# 1,00 % mensual ≈ 12,68 % anualTASA_ALT =0.0075# 0,75 % mensual ≈ 9,38 % anualHORIZONTE_LARGO =60# mesesHORIZONTES_CORTE = [12, 24, 36, 60]# Vectores que ya construyó la sección de modelado predictivoF = cal_hold["frequency_cal"].valuesR = cal_hold["recency_cal"].valuesT = cal_hold["T_cal"].valuesM = cal_hold["monetary_value_cal"].values# Ticket esperado por cliente: Gamma-Gamma para freq>0, media poblacional para freq=0ticket_pop =float(gg_check["monetary_value_cal"].mean())ticket_esp = np.full(len(F), ticket_pop, dtype=float)mask_pos = F >0ticket_esp[mask_pos] = np.asarray( ggf.conditional_expected_average_profit(F[mask_pos], M[mask_pos]))# Compras acumuladas hasta el final de cada mes (vectorizado por cliente)compras_acum = np.zeros((HORIZONTE_LARGO +1, len(F)))for mes inrange(1, HORIZONTE_LARGO +1): t_dias = mes *30# convención 30 días/mes (la misma que usa lifetimes) out = bgf.conditional_expected_number_of_purchases_up_to_time(t_dias, F, R, T) compras_acum[mes] = np.asarray(out)compras_mes = np.diff(compras_acum, axis=0) # shape (60, n)def descontar(compras_mes: np.ndarray, ticket: np.ndarray, tasa: float):"""Devuelve valor descontado mensual y acumulado dada una tasa mensual.""" descuento = (1+ tasa) ** np.arange(1, compras_mes.shape[0] +1) valor_mes = compras_mes * ticket / descuento[:, None]return valor_mes, np.cumsum(valor_mes, axis=0)valor_mes_base, valor_acum_base = descontar(compras_mes, ticket_esp, TASA_BASE)valor_mes_alt, valor_acum_alt = descontar(compras_mes, ticket_esp, TASA_ALT)# DataFrame de salida, una fila por clienteseg = pd.DataFrame({"customer_id": cal_hold.index.astype(str)})seg["pAlive"] = np.asarray(palive)seg["frequency_cal"] = Fseg["recency_cal"] = Rseg["T_cal"] = Tseg["ticket_esperado"] = ticket_espfor h in HORIZONTES_CORTE: seg[f"compras_{h}m"] = compras_acum[h] seg[f"valor_{h}m_r100"] = valor_acum_base[h -1] seg[f"valor_{h}m_r075"] = valor_acum_alt[h -1]# Horizonte al 90 % del valor a 60 meses (tasa base)val_60_base = valor_acum_base[-1]umbral = val_60_base *0.90mask_val_pos = val_60_base >0superado = valor_acum_base >= umbral[None, :]mes_umbral = np.where(mask_val_pos, np.argmax(superado, axis=0) +1, -1)seg["horizonte_90pct"] = mes_umbralprint(seg[["pAlive", "frequency_cal", "ticket_esperado","valor_12m_r100", "valor_60m_r100", "horizonte_90pct"]].describe().round(2).to_string())
Los quintiles se construyen sobre el valor esperado a 12 meses (tasa base) entre los clientes con frecuencia >0 en calibración. Los demás (los que sólo aparecen una vez en el periodo) van a una bandeja propia: el modelo todavía les asigna un valor esperado, pero su lectura gerencial es distinta y conviene no diluirlos en los quintiles.
mask_calib = seg["frequency_cal"] >0# Quintiles sobre clientes con frecuencia repetidaseg["quintil"] ="Sin compras repetidas"etiquetas = ["Q1 (más bajo)", "Q2", "Q3", "Q4", "Q5 (más alto)"]quintiles = pd.qcut( seg.loc[mask_calib, "valor_12m_r100"].rank(method="first"),5, labels=etiquetas).astype(str)seg.loc[mask_calib, "quintil"] = quintiles.values# Top 100 absoluto sobre el valor a 12m base (puede solapar con Q5)top100_ids = seg.nlargest(100, "valor_12m_r100")["customer_id"].tolist()seg["top100"] = seg["customer_id"].isin(top100_ids)print("Distribución por segmento:")print(seg["quintil"].value_counts().reindex(["Sin compras repetidas"] + etiquetas))print(f"\nClientes en Top 100 absoluto: {seg['top100'].sum()}")
Distribución por segmento:
quintil
Sin compras repetidas 1618
Q1 (más bajo) 663
Q2 663
Q3 663
Q4 663
Q5 (más alto) 663
Name: count, dtype: int64
Clientes en Top 100 absoluto: 100
Tabla resumen por segmento
Esta es la tabla que un comité de dirección quiere ver de un vistazo. Una fila por bandeja (los cinco quintiles, los clientes “sin compras repetidas”, la fila Top 100 y el total) y, en columnas, las métricas que de verdad importan: tamaño del grupo, pAlive media, ticket esperado, valor esperado a 12 y 60 meses, peso del grupo en el valor total a 60 meses y horizonte mediano al 90 %.
Lee la tabla con calma. Tres lecturas merecen el rato:
Primero, la concentración. El quintil 5 se lleva, en una base no contractual típica como ésta, una fracción del valor total a 60 meses muy desproporcionada respecto a su 20 % de clientes. La fila Top 100 (en torno al 2-3 % de los clientes con frecuencia repetida) suele concentrar entre el 15 % y el 30 % del valor total. Es la misma asimetría que ya viste en 1.5 con el segmento Champions de RFM, ahora medida en valor esperado a futuro y no en histórico. No es un defecto: es la estructura de cualquier base de clientes y la razón por la que pagar lo mismo por captar a cualquiera es una pésima idea.
Segundo, la pAlive media de cada quintil. En general (y es lo que vas a ver) los quintiles altos tienen pAlive alta y los bajos no. Esto es tautológico en parte, porque el modelo construye el valor esperado precisamente a partir de la pAlive y la frecuencia. Pero si te encuentras un quintil con pAlive sorprendentemente baja para su valor esperado (por ejemplo, alguien con ticket enorme pero pocas compras y silencio reciente), tienes una bandera roja: el valor esperado se sostiene en una hipótesis frágil y conviene mirar cliente a cliente.
Tercero, el horizonte al 90 %. Es la respuesta más limpia que el modelo puede darte a la pregunta «¿durante cuánto tiempo voy a monetizar a este cliente?». Un horizonte corto (12-18 meses) significa que el grueso del valor se materializa rápido y que el riesgo de cambios en el comportamiento futuro es bajo (porque ya casi no esperas comportamiento futuro). Un horizonte largo (40-60 meses) significa que el valor se distribuye más a lo largo del tiempo y, por tanto, es más sensible a la tasa de descuento, a cambios en el patrón de compra y a la propia estabilidad del modelo a largo plazo. Para tu equipo de retención, un Q5 con horizonte corto es objetivo prioritario y de bajo riesgo; un Q5 con horizonte largo, prioritario también, pero conviene revisar la previsión más a menudo.
Sensibilidad a la tasa de descuento
Bajar la tasa de descuento aumenta el valor a horizontes largos, porque los flujos lejanos pesan más. La pregunta práctica es cuánto. Lo veo aquí en paralelo, segmento a segmento.
valor_12m_r100 valor_60m_r100 valor_12m_r075 valor_60m_r075 delta_60m_pct
quintil
Sin compras repetidas 151.78 NaN 154.19 NaN NaN
Q1 (más bajo) 191.78 738.30 194.83 790.29 7.04
Q2 492.56 1898.05 500.38 2031.78 7.05
Q3 876.74 3383.19 890.67 3621.71 7.05
Q4 1619.18 6261.01 1644.91 6702.77 7.06
Q5 (más alto) 7186.69 27884.84 7301.01 29855.06 7.07
El efecto de mover la tasa del 1 % al 0,75 % mensual será mayor en los quintiles altos y, sobre todo, en los clientes con horizonte al 90 % largo, porque son los que tienen más valor lejano que descontar. Si alguna fila te muestra una variación superior al 15 % al mover la tasa unos pocos puntos básicos, no estás ante una “buena estimación con dos tasas posibles” sino ante una cifra que descansa demasiado en la hipótesis financiera. La conclusión práctica: si vas a usar este número para defender un business case, declara la tasa antes que la cifra.
De los clientes calibrados a los nuevos: cómo accionar el análisis
Hasta aquí el modelo te dice qué esperar de los clientes que ya conoces: cada fila de segmentos_valor.parquet lleva su pAlive, su valor a 12 meses y su quintil. Pero las decisiones de marketing rara vez se limitan al stock de la base actual: hay que pronunciarse también sobre el cliente que llegará el mes que viene y, sobre todo, sobre cuánto se puede pagar por captarlo. Cierro el apartado de segmentos enseñándote cómo accionar el análisis en clientes nuevos, usando como ejemplo de manual a los clientes que aparecieron por primera vez después del corte de calibración (ejemplo elegido a propósito porque, recuerda la decisión 5 de 1.8.1, esos clientes quedaron deliberadamente fuera del modelo).
# 1) El hueco concreto: clientes con primera compra después del corteprimeras = trans_pos.groupby("customer_id")["invoice_date"].min()post_corte = primeras[primeras > fecha_corte_cal]n_post =len(post_corte)n_total = trans_pos["customer_id"].nunique()print(f"Corte de calibración: {fecha_corte_cal.date()}")print(f"Clientes con 1ª compra ANTES del corte (en seg): {len(seg):>5,}")print(f"Clientes con 1ª compra DESPUÉS del corte: {n_post:>5,} "f"({n_post/n_total*100:.1f}% del total con compras positivas)")print("Los segundos no tienen pAlive ni valor esperado individuales: el modelo no los vio.")# 2) Cifra incondicional: lo que el modelo espera de un cliente "recién nacido"compras_acum_nuevo = np.zeros(HORIZONTE_LARGO +1)for mes inrange(1, HORIZONTE_LARGO +1): t_dias = mes *30 compras_acum_nuevo[mes] =float(bgf.expected_number_of_purchases_up_to_time(t_dias))compras_mes_nuevo = np.diff(compras_acum_nuevo)descuento_base = (1+ TASA_BASE) ** np.arange(1, HORIZONTE_LARGO +1)valor_mes_nuevo = compras_mes_nuevo * ticket_pop / descuento_basevalor_acum_nuevo = np.cumsum(valor_mes_nuevo)print(f"\nValor esperado de un CLIENTE NUEVO MEDIO (tasa base = {TASA_BASE*100:.2f}%/mes):")print(f" Excluye el primer ticket por convención de BG/NBD; súmale {ticket_pop:,.2f} si lo necesitas incluido.")for h in HORIZONTES_CORTE:print(f" {h:>2d} m: {valor_acum_nuevo[h-1]:>9,.2f}")# 3) Referencias para situar la magnitudval_12m_q3 = seg.loc[seg["quintil"] =="Q3", "valor_12m_r100"].mean()val_12m_top100 = seg.loc[seg["top100"], "valor_12m_r100"].mean()print(f"\nReferencias para situar la cifra (a 12 meses):")print(f" Cliente nuevo medio: {valor_acum_nuevo[11]:>9,.2f}")print(f" Q3 medio (mitad de la base): {val_12m_q3:>9,.2f}")print(f" Top 100 medio (cabecera del ranking): {val_12m_top100:>9,.2f}")
Corte de calibración: 2011-06-01
Clientes con 1ª compra ANTES del corte (en seg): 4,933
Clientes con 1ª compra DESPUÉS del corte: 945 (16.1% del total con compras positivas)
Los segundos no tienen pAlive ni valor esperado individuales: el modelo no los vio.
Valor esperado de un CLIENTE NUEVO MEDIO (tasa base = 1.00%/mes):
Excluye el primer ticket por convención de BG/NBD; súmale 418.78 si lo necesitas incluido.
12 m: 1,305.75
24 m: 2,388.87
36 m: 3,325.30
60 m: 4,859.02
Referencias para situar la cifra (a 12 meses):
Cliente nuevo medio: 1,305.75
Q3 medio (mitad de la base): 876.74
Top 100 medio (cabecera del ranking): 25,580.01
La cifra que te aparece arriba (el valor esperado de un cliente nuevo medio) no es magia ni una hipótesis nueva: es la otra cara del mismo modelo que ya calibraste. BG/NBD, además de la respuesta condicional «dado este F, R, T, ¿qué espero de este cliente?», entrega la respuesta no condicional «¿qué espero de un cliente cualquiera de los que esta base produce?». La primera responde a decisiones sobre clientes individuales (a quién contacto del stock actual); la segunda, a decisiones sobre la base como tal (cuánto puedo pagar por que entren más clientes parecidos a los que ya tengo).
Hay tres formas de accionar este cálculo operativamente, ordenadas de menos a más sofisticadas, y cada una sirve para un tipo distinto de decisión:
Cifra incondicional como referencia de planificación. Es lo que acabas de obtener. Es la cifra que necesitas para defender o destruir un business case de captación: si una campaña te trae clientes a un coste por adquisición (CAC) superior al valor esperado de un cliente nuevo medio, estás destruyendo valor en agregado, por mucho que algunos clientes individuales acaben siendo Champions. La cifra a 12 meses encaja con el horizonte presupuestario habitual; la de 60 meses (más alta, pero también más sensible a la tasa de descuento, como ya te recordó 1.10.4) es más cómoda para discusiones estratégicas y para pricing de programas de fidelización.
Asignación por proxy al primer contacto. Si en el momento de la captación tienes alguna información observable (canal de origen, país, categoría de la primera compra, importe del primer ticket), puedes ir más allá del agregado: asignas al cliente nuevo al segmento de 1.10.3 al que más se parece. Para que esto funcione necesitas evidencia previa de que esas variables observables al inicio se correlacionan con el segmento final. En retail esa evidencia suele existir (los clientes con primer ticket alto tienden, en promedio, a quintiles altos), pero conviene comprobarlo en tus datos antes de fiarse: una correlación débil con el proxy te lleva, una vez más, a quedarte con la cifra incondicional y a otra cosa.
Refresco continuo a medida que llega historia. Con la primera, segunda y tercera compra, el cliente acumula su F, R, T y BG/NBD pasa, por construcción, de la cifra incondicional a una individualizada cada vez más afilada. Operativamente, esto se traduce en un workflow sencillo: recalibras el modelo cada N meses (3, 6 o 12 según volumen), reasignas predicciones a todos los clientes (los nuevos pasan de la cifra incondicional a la condicional cuando ya tienen suficiente historia para que el cálculo sea estable) y reescribes predicciones_clv.parquet y segmentos_valor.parquet. Tu CRM lee esas tablas y actúa.
Una salvedad sobre el primer ticket. BG/NBD modela compras repetidas por convención: el primer ticket no entra en E[X(t)]. Si necesitas el valor total de la captación (porque el CAC se paga por adquirir esa primera compra), súmale a la cifra incondicional el ticket_pop que calculaste en 1.10.1. La omisión del primer ticket es un convenio del modelo, no un olvido del cálculo, y conviene tenerla presente cuando el dato vaya a una hoja de cálculo financiera de marketing.
Actualización de CARD.md con todos los artefactos
card_extra =f"""## Artefactos adicionales (modelado, validación y segmentación)- `predicciones_clv.parquet`: una fila por cliente con frequency/recency/T de calibración, pAlive, número esperado de compras a 180 días, ticket esperado y valor esperado hacia adelante a 12 meses (generado en el modelado predictivo).- `calibration_plot.svg`: gráfico de calibración por decil generado en la validación.- `segmentos_valor.parquet`: una fila por cliente con quintil de valor, proyecciones a 12, 24, 36 y 60 meses, dos tasas de descuento en paralelo y horizonte al 90 % del valor a 60 meses (generado en los segmentos de valor).## Decisiones del modelado predictivo5. **Corte calibración / holdout:** 2011-06-01 (18 meses de calibración, ~190 días de holdout).6. **Cancelaciones en el ajuste:** excluidas (modelos asumen proceso de conteo no negativo).7. **Modelo principal:** BG/NBD + Gamma-Gamma (no contractual, frecuencia razonable, comportamiento estable).## Cifras agregadas del ajuste y validación- Clientes en summary calibración/holdout: {len(predicciones):,}- Parámetros BG/NBD: r={bgf.params_['r']:.3f}, alpha={bgf.params_['alpha']:.3f}, a={bgf.params_['a']:.3f}, b={bgf.params_['b']:.3f}- Parámetros Gamma-Gamma: p={ggf.params_['p']:.3f}, q={ggf.params_['q']:.3f}, v={ggf.params_['v']:.3f}- Ratio predicha/observada (validación agregada): {total_predicho/max(total_observado,1):.3f}- Lift modelo vs RFM (top 100): {compras_top_modelo/max(compras_top_rfm, 0.001):.2f}x- Intersección top 100 modelo vs RFM: {len(I)}/{N} ({len(I)/N:.0%})"""withopen(OUT_DIR /"CARD.md", "a", encoding="utf-8") as f: f.write(card_extra)print("CARD.md actualizado con el bloque del modelado, validación y segmentación.")
CARD.md actualizado con el bloque del modelado, validación y segmentación.
Y ahora, ¿qué?
Has cerrado el caso práctico extremo a extremo: auditoría, limpieza, cohortes, RFM, calibración de BG/NBD y Gamma-Gamma, generación de pAlive y del valor esperado por cliente, validación del modelo por cuatro vías estadísticas y un ejercicio gerencial sobre el top 100, y segmentación accionable por quintiles de valor con dos tasas de descuento en paralelo. Construir, validar, accionar, en ese orden y sin saltarse ninguno de los tres. Eso es, literalmente, lo que pediría un proyecto de CLV serio en cualquier organización.
Los cinco artefactos persistidos en materiales/cap05/outputs/ (las tres tablas iniciales, predicciones_clv.parquet y segmentos_valor.parquet) son la base de los capítulos siguientes:
Cap. 8 (segmentación basada en valor). Va a usar segmentos_valor.parquet como entrada principal y a comparar la segmentación basada en pAlive + valor esperado hacia adelante con la canónica de RFM.
Cap. 10 (decisiones de retención). Va a usar pAlive, el valor esperado a 12 meses y el horizonte al 90 % para priorizar el presupuesto de retención.
Cap. 12 (la brecha modelo-decisión). Va a poner nombre, en clave organizativa, al problema que ya has visto aparecer aquí: el ejercicio gerencial del top 100 no es solo un diagnóstico estadístico, es una pelea por la decisión.
Si llegas al cap. 8 con la sensación de “ya tengo el dato; ahora dime cómo se traduce en acción”, vas en la dirección correcta. Y si te has quedado con la sensación contraria de “esto del modelado predictivo es un mundo que aún necesito masticar más”, también está bien: vuelve, reejecuta el caso con otras decisiones (otra ventana, otro corte temporal, sin filtrar cancelaciones, lo que sea) y mira cómo cambian los números. Decidir, documentar la decisión y dejar un rastro defendible no es solo un eslogan: es la única forma que conozco de aprender a tomar decisiones de modelado con criterio.